
말랑코딩
StyleGAN은 얽힘(entanglement)을 어떻게 해결했을까? 본문
잠재 변수(latent variable) z 란?

잠재 변수 z
- 정규 분포 또는 균일 분포에서 샘플링되며 생성된 콘텐츠의 유형과 스타일을 결정하는 요인을 포함합니다.
Training 에 있어 z가 얽히지 않아야 하는 이유
- 일반적으로 머신 러닝(ML)은 모델 교육을 더 쉽게 만드는 다른 요소와 독립적인 잠재 요소를 좋아합니다.
- 예를 들어, 키와 체중은 크게 얽혀 있습니다(키가 큰 사람은 더 무겁습니다). 따라서 키와 몸무게로 계산한 체질량지수(BMI)가 비만과 관련하여 보다 일반적으로 사용됩니다.
- 얽히지 않은 요인은 또한 모델을 올바르게 해석하기 쉽게 만들고, 모델을 덜 복잡하게 합니다.
z가 얽히지 않게 하기 위한 피쳐 분포 형태
- GAN에서 z 의 분포 는 실제 이미지의 잠재 인자 분포와 유사해야 합니다.
- 대신 정규 분포 또는 균일 분포로 z 를 샘플링 하면 최적화된 모델 에서 유형 및 스타일을 넘어서는 정보를 포함하기 위해 z 가 필요할 수 있습니다.
- 예를 들어 군인의 초상화를 생성하고 남성다움과 머리 길이라는 두 가지 잠재 요소를 사용하여 훈련 데이터 세트의 데이터 분포를 시각화해 보겠습니다.
- 아래의 누락된 왼쪽 상단 모서리는 남성 병사가 긴 머리를 가질 수 없음을 나타냅니다.

- StyleGAN에서는 매핑 네트워크라는 딥 네트워크를 적용하여 잠재 z 를 중간 잠재 공간 w 로 변환합니다 .

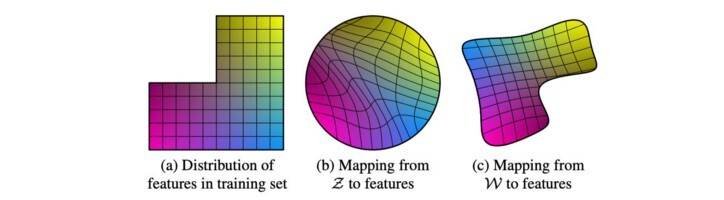
- 개념적으로 StyleGAN은 균일하거나 정규 분포로 샘플링할 수 있는 공간(아래 중간)을 이미지를 쉽게 생성하는 데 필요한 잠재 특징 공간(왼쪽)으로 왜곡합니다. -->어떤 방식으로 왜곡시키는지?
- 이 매핑 네트워크의 목표는 생성기에서 쉽게 렌더링할 수 있는 얽힌 기능을 만들고 훈련 데이터 세트에서 발생하지 않는 기능 조합을 피하는 것입니다.
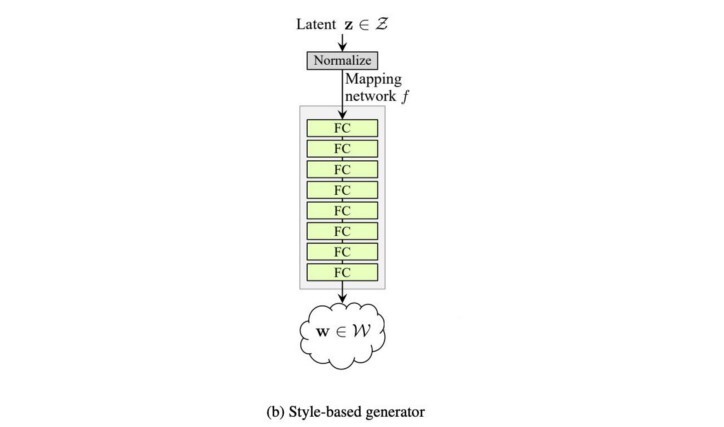
- StyleGAN은 8개의 완전히 연결된 레이어(FC)를 사용하여 z 를 이 중간 잠재 공간으로 변환하기 위해 매핑 네트워크 f 를 도입합니다 . w 는 새로운 z ( z ') 로 볼 수 있습니다 . 이 네트워크를 통해 512-D 잠재 공간 z 는 512-D 중간 잠재 공간 w 로 변환됩니다 .
->위 그림에서, (b) Z로부터 feature에 매핑하면 학습셋의 분포(a)를 따르지 못하는데, (c)W로부터 feature에 매핑하면 학습셋과 어느정도 비슷한 분포를 따르게 된다. 즉, Z를 W로 만드는 과정이 무엇인지 알 필요가 있음!
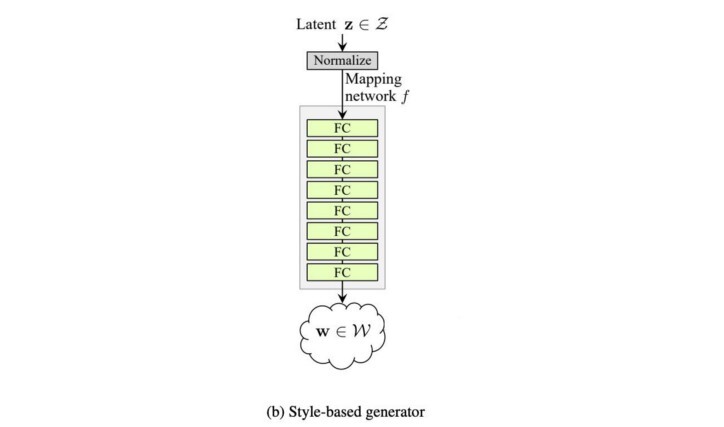
스타일 기반 생성기
잠재변수 z 는 스타일 기반 생성기에서 개별적으로 학습된 아핀 연산 A 를 적용하여 각 레이어에서 w 를 변환 합니다. 이렇게 변환된 w 는 공간 데이터에 적용되는 스타일 정보(무슨말?)로 작용합니다.

ProGAN에 Method 하나씩 바꿔가며 성능 측정
StyleGAN 논문에서는 Progress GAN 네트워크 설계( 세부 사항 )로 시작하여 Adam 최적화 프로그램을 포함한 많은 하이퍼파라미터를 재사용합니다. 그런 다음 연구원은 모델 성능이 개선되었는지 확인하기 위해 설계 변경을 실험합니다.

첫 번째 개선 사항(B)은 판별기 및 생성기 네트워크 모두에서 가장 가까운 이웃 업/다운샘플링을 쌍선형 샘플링으로 대체하는 것입니다. 하이퍼파라미터가 더 조정되고 모델도 더 오래 훈련됩니다.
C) B+ Add mapping and styles
두 번째 개선 사항(C)은 매핑 네트워크 및 스타일 추가입니다. 이는 AdaIN(적응형 인스턴스 정규화)이 공간 데이터에 스타일을 적용할 때 PixelNorm을 대체합니다.

AdaIN(적응형 인스턴스 정규화)은 다음과 같이 정의됩니다.

여기서 입력 기능 맵은 먼저 인스턴스 정규화로 정규화됩니다. 그런 다음 StyleGAN은 각 정규화된 공간 기능 맵을 스타일 정보에 따라 크기 조정하고 바이어스합니다. ( μ 와 σ 는 각각 입력 특징 맵 xᵢ 의 평균과 표준편차입니다 .) 각 레이어에서 StyleGAN은 한 쌍의 스타일 값( y ( s, i )과 y ( b, i ))을 척도로 계산하고 공간 특징 맵 i 에 스타일을 적용하기 위한 w 의 편향 . 정규화된 기능은 공간 위치에 적용되는 스타일의 양에 영향을 줍니다.
바닐라 GAN에서 첫 번째 레이어에 대한 입력은 잠재 인자 z 입니다. 경험적 결과에 따르면 StyleGAN의 첫 번째 레이어에 변수 입력을 추가해도 아무런 이점이 없으므로 상수 입력으로 대체됩니다.
D) C + Remove traditional input
개선(D)을 위해 첫 번째 레이어에 대한 입력은 차원이 4x4x512인 학습된 상수 행렬로 대체됩니다.

StyleGAN 논문에서 “Style”은 포즈, 아이덴티티와 같은 데이터의 주요 속성을 나타냅니다.
E) D+ Add noise inputs
개선 사항(E)에서 SytleGAN은 확률적 변동 을 생성할 때 공간 데이터에 노이즈를 도입합니다 .

예를 들어, 추가된 노이즈는 실험에서 머리카락(아래), 수염, 주근깨 또는 피부 모공의 위치에 변형을 만드는 것으로 관찰됩니다.

예를 들어, 8×8 공간 레이어의 경우 상관되지 않은 가우스 노이즈를 포함하는 요소로 8×8 행렬이 생성됩니다. 이 매트릭스는 모든 기능 맵에서 공유됩니다. 그러나 StyleGAN은 각 기능 맵에 대해 별도의 스케일링 요소를 학습하고 이전 레이어의 출력에 추가하기 전에 노이즈 매트릭스와 곱합니다.

노이즈는 노이즈가 없거나 특정 해상도에만 적용된 경우와 비교할 때 아래에 설명된 이점을 가진 렌더링 변형을 만듭니다. StyleGAN 논문은 또한 다른 GAN 방법에서 자주 볼 수 있는 반복적인 패턴을 완화한다고 제안합니다.

-> b) noise 생략은 featureless 하게 만들고, 회화적으로 보이게 만들고, d) coarse noise 는 라지스케일의 헤어 컬링과 더 큰 배경 피쳐의 모습을 만들어내고, c) fine noise 는 더 정교한 헤어 컬과, 정교한 배경 디테일, 피부 모공까지 표현하다는 걸 알수 있습니다.
마지막 개선 사항(E)은 혼합 정규화에 있습니다.
스타일 믹싱 및 믹싱 정규화
이전에는 잠재 요소 z를 생성 하고 스타일을 유도할 때 단일 소스로 사용했습니다. Mixing regularization 을 사용하면 특정 공간 해상도에 도달한 후 스타일을 유도 하기 위해 다른 잠재 인자 z 2로 전환합니다 .

아래와 같이 이미지 "소스 B"를 생성하는 잠재 요소를 사용하여 거친 공간 해상도(4x4 ~ 8x8) 스타일을 유도하고 "소스 A"의 스타일을 사용하여 더 미세한 공간 해상도를 만듭니다. 따라서 생성된 이미지는 소스 B의 포즈, 일반적인 헤어스타일, 얼굴 모양 및 안경과 같은 높은 수준의 스타일을 가지면서 모든 색상(눈, 머리카락, 조명) 및 미세한 얼굴 특징은 A와 유사합니다.

소스 B에서 중간 해상도(16×16 ~ 32×32)의 스타일을 사용하는 경우 B에서 작은 스케일의 얼굴 특징, 헤어 스타일, 눈 뜨고/감기, 이미지 A에서 포즈, 일반적인 얼굴 모양 및 안경을 상속합니다. 보존됩니다. 마지막 열에서는 색 구성표와 미세 구조에 주로 영향을 미치는 소스 B의 미세 스타일(64×64 ~ 1024×1024 해상도)을 복사합니다.

훈련에서 이미지의 특정 비율은 하나가 아닌 두 개의 임의의 잠재 코드를 사용하여 생성됩니다.
훈련
FFHQ(사람 얼굴 데이터 세트 — Flickr-Faces-HQ)는 연령, 민족, 이미지 배경 및 안경, 모자 등과 같은 액세서리와 같은 더 나은 적용 범위를 가진 CelebA-HQ에 비해 더 높은 품질의 데이터 세트입니다. StyleGAN에서는 CelebA-HQ 데이터 세트는 손실 함수로 WGAN-GP를 사용하여 훈련되는 반면 FFHQ는 아래의 R₁ 정규화와 함께 포화되지 않은 GAN 손실을 사용합니다.
W의 자르기(truncation) 트릭
z 또는 w의 낮은 확률 밀도 영역은 이를 정확하게 학습하기에 충분한 훈련 데이터가 없을 수 있습니다.
따라서 이미지를 생성할 때 이러한 영역을 피하여 변형을 희생시키면서 이미지 품질을 향상시킬 수 있습니다. 이것은 z 또는 w 를 잘라서 수행할 수 있습니다 . StyleGAN에서는 다음을 사용하여 w 에서 수행됩니다 .
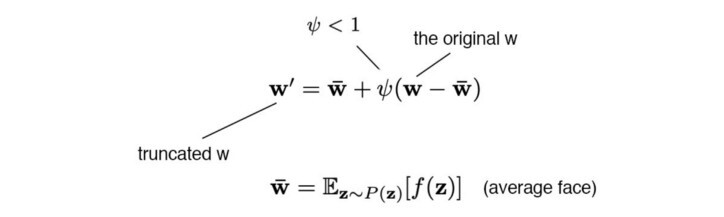
여기서 ψ는 스타일 척도 라고 합니다 .
그러나 절단은 저해상도 레이어에서만 수행됩니다(예: ψ = 0.7인 4×4 ~ 32×32 공간 레이어). 이렇게 하면 고해상도 세부 정보가 영향을 받지 않습니다.
ψ를 0으로 설정하면 아래와 같이 평균 면이 생성됩니다. ψ 값을 조정하면 관점, 안경, 나이, 색상, 머리 길이, 성별과 같은 속성이 어떻게 바뀌는지 알 수 있습니다.

'논문' 카테고리의 다른 글
| [논문 리뷰] Stitch it in Time: GAN-Based Facial Editing of Real Videos (0) | 2022.04.18 |
|---|
